









ダイナミックな実写イラストを生成するチュートリアル
使用したAI
Custom Model
実写系モデルで生成する時に、ダイナミックな構図やポーズを出すのがなかなか難しいのですが、以下の手順で生成すると結構いい感じの構図で生成できますので共有します。
おおまかに手順は以下になります。
①t2iでアニメ系モデルで画像生成
②t2iでモデルをリアル系モデルに変更しControlnetのtileで①で生成した画像を指定して生成
③multidiffusionで高解像度化
④i2iで修正
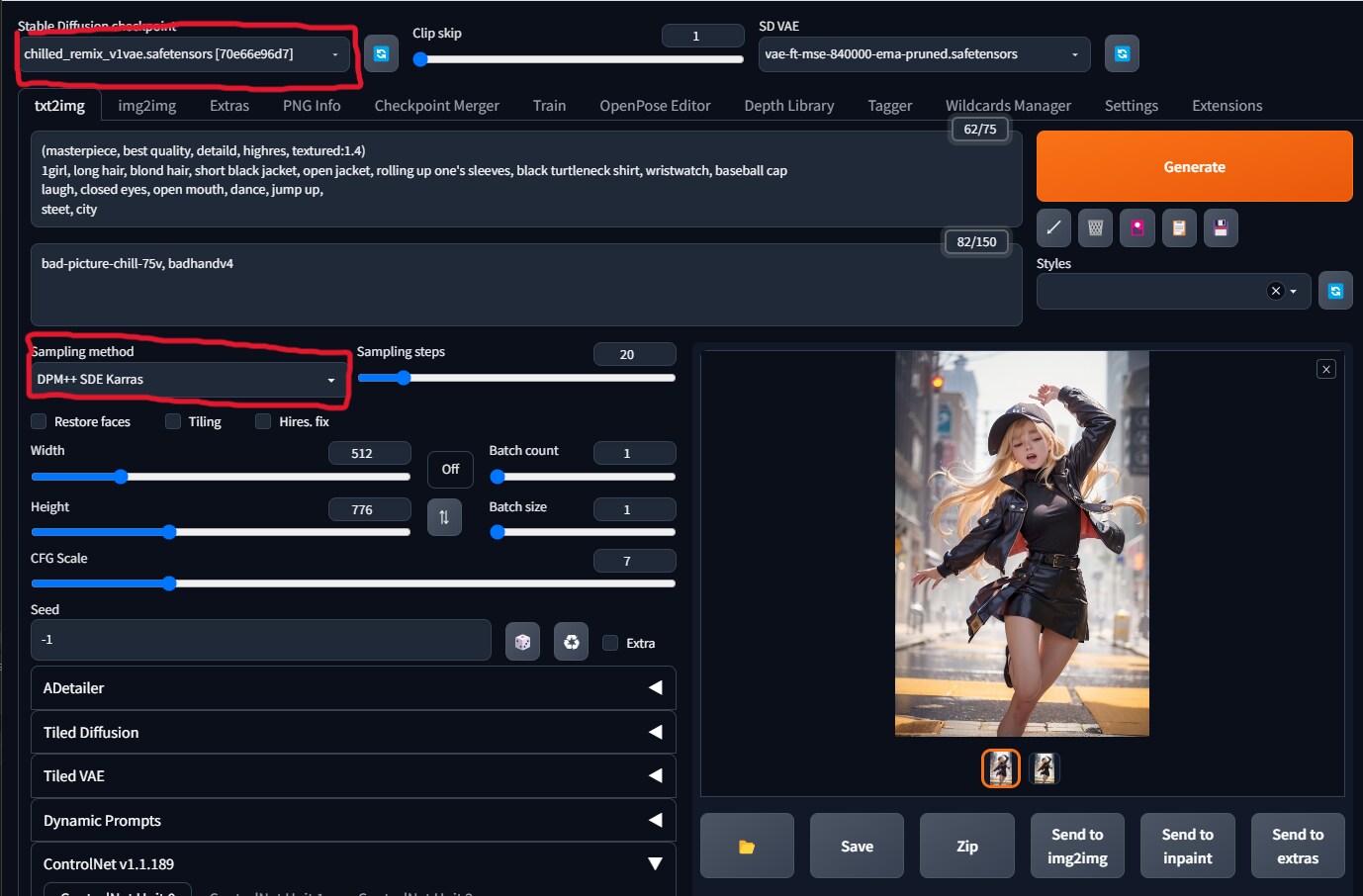
①実写系モデルよりアニメ系モデルの方がダイナミックな構図やポーズをとりやすい傾向にあるので、まずは元となる画像をt2iでアニメ系モデルを使って生成します。参考はCounterfeit-v3.0を使用しています。
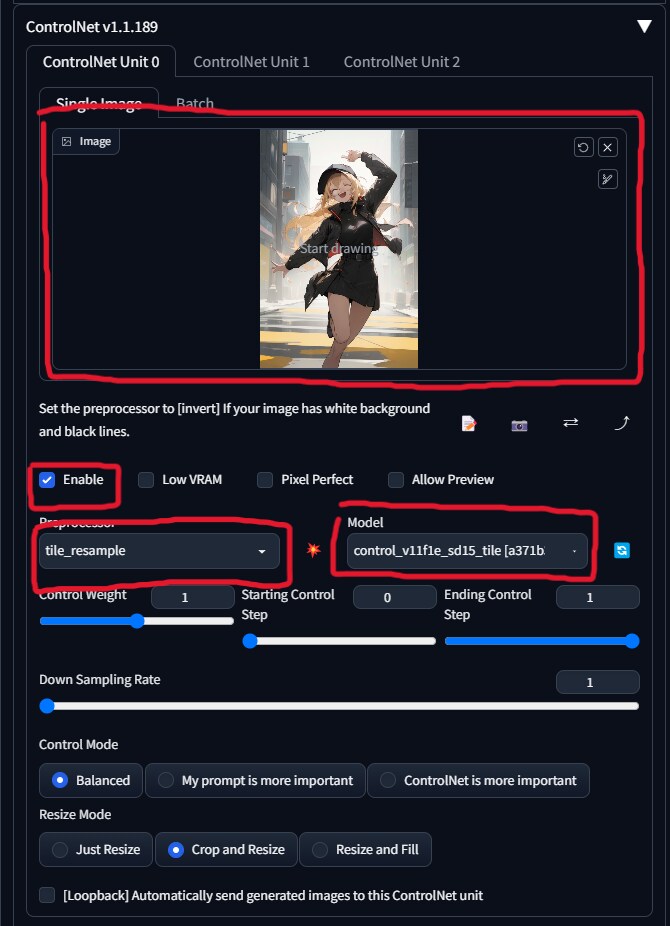
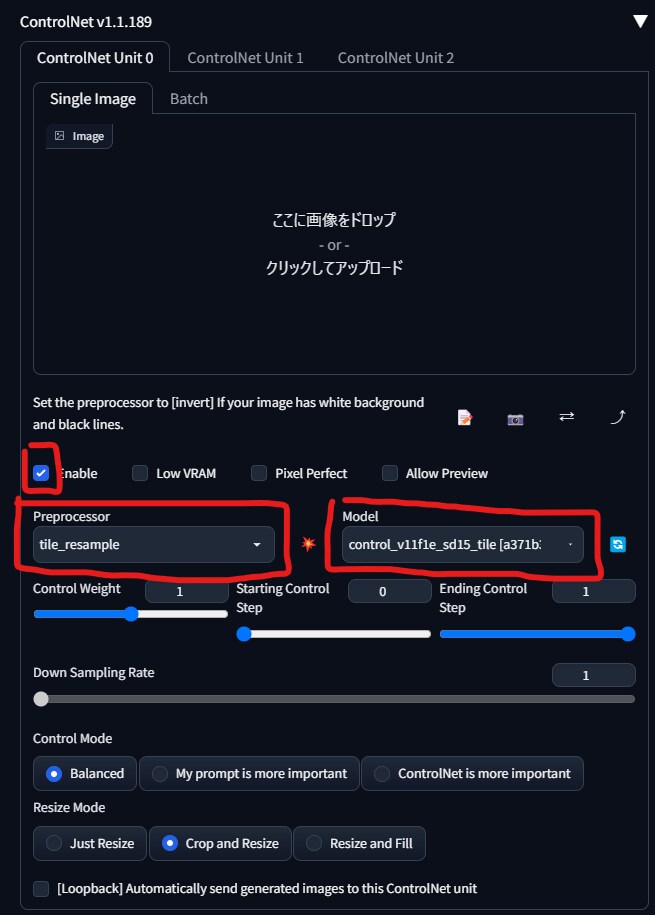
②t2iでモデルを実写系モデルに変更し、ControlnetをEnableにしPreprocessorをtile_resampleに、Modelをtile用のモデルにします。tile_resampleは元画像を忠実に再現してくれるのですが、モデルを変えることでアニメ調からリアル調にいい感じに変換してくれます。
その他の細かいパラメーターはいじらなくても大丈夫です。
参考は、モデルをchilled_remixに、Sampling methodをDPM++ SDE Karrasにしています。それ以外は同じです。
以降は高解像度化のお話なのですでにやり方が確立されている方はスルーしてもらって大丈夫です。
③生成した画像を高解像度化します。t2iで生成した画像をSend to img2imgのボタンでi2iに転送します。
ここではmultidiffusionを使います。
multidiffusion
https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111
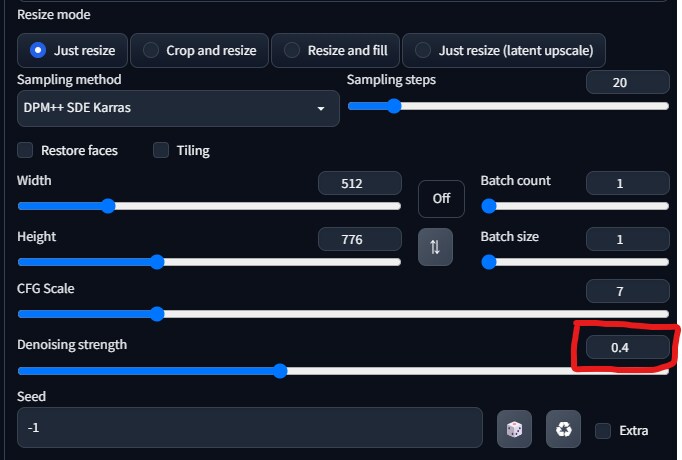
最初にdenoising strengthを0.4~0.5あたりに設定します。これ以上の数値にすると元の画像からかけ離れた画像が生成されやすいのでこれくらいがベターです。
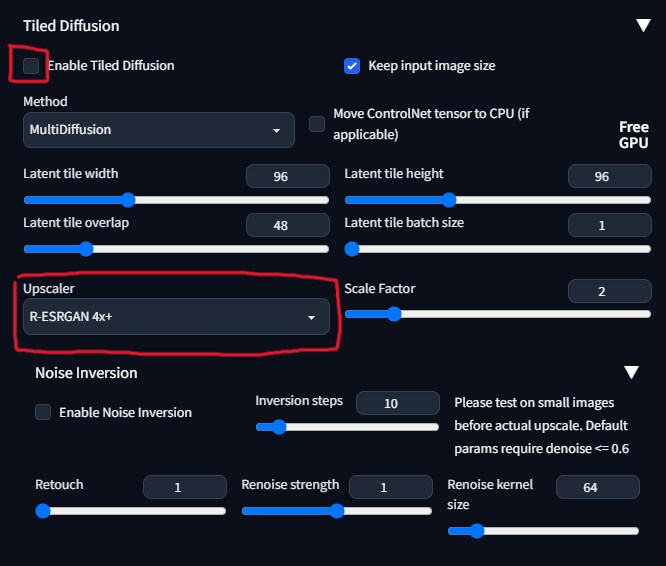
次にTiled DiffusionをEnableにしUpscalerをR-ESRGAN 4x+にします。
Upscalerはお好みで選んでもらって大丈夫ですが、私は実写系はR-ESRGAN 4x+、アニメ系はR-ESRGAN 4x+ Anime6Bを使う事が多いです。
より高解像度にしたい場合はScale Factorで倍率を上げてみましょう。上げすぎると破綻しやすいので注意です。
その他はデフォです。
次にTiled VAEをEnableにします。これはVRAMの使用量を抑えてくれるものなので無条件にEnableにしてしまってOKです。
その他はデフォです。
次にcontrolnetをEnableにし、Preprocessorをtile_resampleにし、Modelをtile用のモデルに指定します。インプットイメージは空の状態で大丈夫です。
controlnetのtileを使うのはmultidiffusionと組み合わせた際によりオリジナルに忠実に生成してくれやすいからです。
設定が出来たら画像を生成します。ここで満足のいく画像が生成できたら完成です。
④生成した画像に気になる部分がある場合はi2iで細かく修正します。顔の修正はface editorやADetailerを使うと綺麗に仕上げてくれます。
face editor
https://github.com/ototadana/sd-face-editor
ADetailer
https://github.com/Bing-su/adetailer
おおまかに手順は以下になります。
①t2iでアニメ系モデルで画像生成
②t2iでモデルをリアル系モデルに変更しControlnetのtileで①で生成した画像を指定して生成
③multidiffusionで高解像度化
④i2iで修正
①実写系モデルよりアニメ系モデルの方がダイナミックな構図やポーズをとりやすい傾向にあるので、まずは元となる画像をt2iでアニメ系モデルを使って生成します。参考はCounterfeit-v3.0を使用しています。
②t2iでモデルを実写系モデルに変更し、ControlnetをEnableにしPreprocessorをtile_resampleに、Modelをtile用のモデルにします。tile_resampleは元画像を忠実に再現してくれるのですが、モデルを変えることでアニメ調からリアル調にいい感じに変換してくれます。
その他の細かいパラメーターはいじらなくても大丈夫です。
参考は、モデルをchilled_remixに、Sampling methodをDPM++ SDE Karrasにしています。それ以外は同じです。
以降は高解像度化のお話なのですでにやり方が確立されている方はスルーしてもらって大丈夫です。
③生成した画像を高解像度化します。t2iで生成した画像をSend to img2imgのボタンでi2iに転送します。
ここではmultidiffusionを使います。
multidiffusion
https://github.com/pkuliyi2015/multidiffusion-upscaler-for-automatic1111
最初にdenoising strengthを0.4~0.5あたりに設定します。これ以上の数値にすると元の画像からかけ離れた画像が生成されやすいのでこれくらいがベターです。
次にTiled DiffusionをEnableにしUpscalerをR-ESRGAN 4x+にします。
Upscalerはお好みで選んでもらって大丈夫ですが、私は実写系はR-ESRGAN 4x+、アニメ系はR-ESRGAN 4x+ Anime6Bを使う事が多いです。
より高解像度にしたい場合はScale Factorで倍率を上げてみましょう。上げすぎると破綻しやすいので注意です。
その他はデフォです。
次にTiled VAEをEnableにします。これはVRAMの使用量を抑えてくれるものなので無条件にEnableにしてしまってOKです。
その他はデフォです。
次にcontrolnetをEnableにし、Preprocessorをtile_resampleにし、Modelをtile用のモデルに指定します。インプットイメージは空の状態で大丈夫です。
controlnetのtileを使うのはmultidiffusionと組み合わせた際によりオリジナルに忠実に生成してくれやすいからです。
設定が出来たら画像を生成します。ここで満足のいく画像が生成できたら完成です。
④生成した画像に気になる部分がある場合はi2iで細かく修正します。顔の修正はface editorやADetailerを使うと綺麗に仕上げてくれます。
face editor
https://github.com/ototadana/sd-face-editor
ADetailer
https://github.com/Bing-su/adetailer
呪文
呪文を見るにはログイン・会員登録が必須です。
イラストの呪文(プロンプト)
jacket partially removed, heart in eye, burnt clothes, holding fishing rod, kanji, doujin cover, pentagram, tape gag, adjusting headwear, red socks, friends, cloud print, coke-bottle glasses, oral invitation, competition school swimsuit, barbell piercing, gradient legwear, prisoner, blood on breasts, wind chime, carrying over shoulder, tape measure, flaming weapon
イラストの呪文(ネガティブプロンプト)
jacket partially removed, heart in eye, burnt clothes, holding fishing rod, kanji, doujin cover, pentagram, tape gag, adjusting headwear, red socks, friends, cloud print, coke-bottle glasses, oral invitation, competition school swimsuit, barbell piercing, gradient legwear, prisoner, blood on breasts, wind chime, carrying over shoulder, tape measure, flaming weapon
- Steps 20
- Scale 7
- Seed 1458069476
- Sampler DPM++ SDE Karras
- Strength
- Noise
- Steps 20
- Scale 7
- Seed 1458069476
- Sampler DPM++ SDE Karras






























![蝶人2[12作品]/werebutterfly 2](https://chichi-pui.akamaized.net/uploads/post_images/originals/da82034c-a581-45c8-8206-9cb3bb7a6a72/d84b0d73-79de-43b5-b8c6-4091df773afc.png?impolicy=thumbnail&w=400&h=400&x=512&y=0)



















































